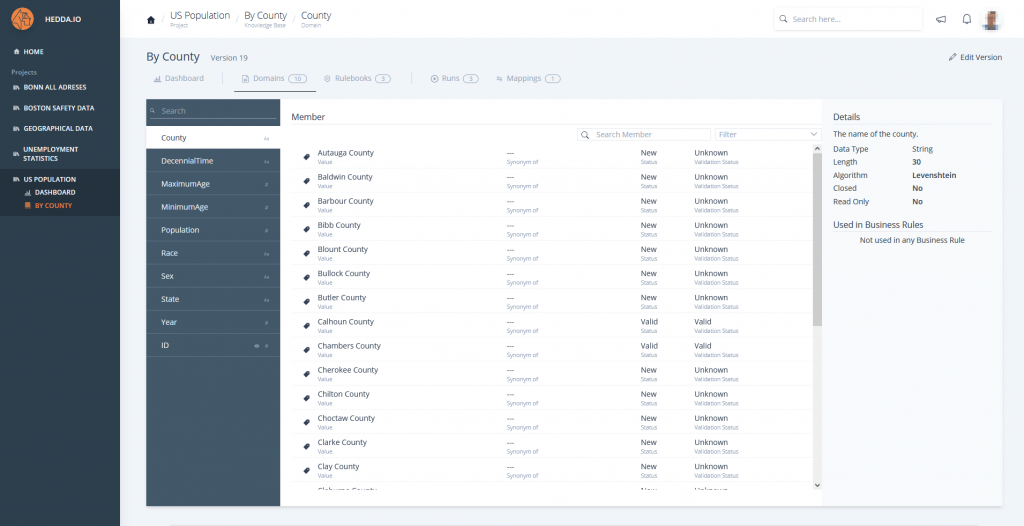
Define and maintain the complete set of valid and invalid members for any business domain – including accepted values, deprecated terms, and meaningful synonyms. HEDDA.IO uses this curated knowledge to automatically validate, classify, and standardize incoming data.
With built-in phonetic matching, similarity scoring, and configurable distance algorithms, the platform identifies inconsistent entries, detects near-duplicates, and aligns variations to a single, trusted reference. This ensures cleaner, harmonized data across all systems and enables consistent downstream analytics and decision-making.
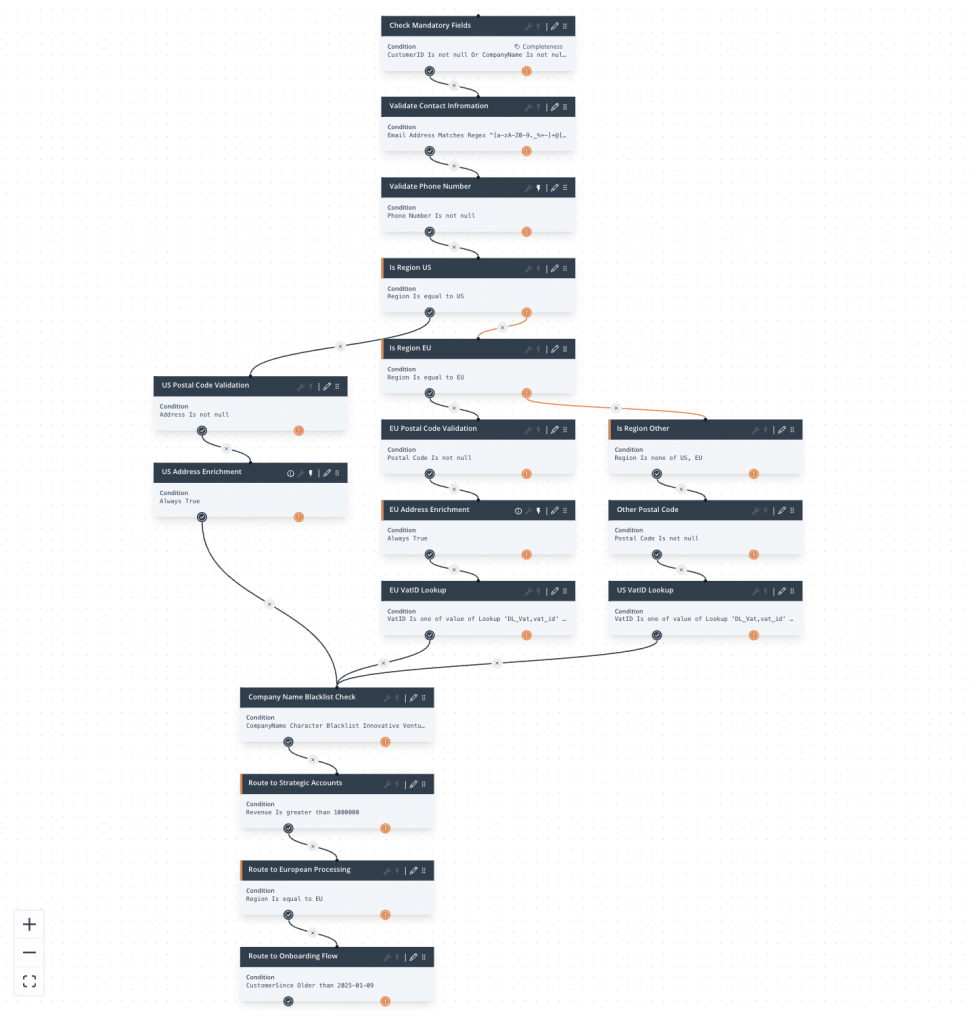
Cleansing and standardizing data is one of the fundamental capabilities of any modern data quality solution. With HEDDA.IO Actions, you gain a powerful and flexible toolkit to handle even the most complex scenarios.
Configure targeted transformations, apply standardized business rules, and automatically correct inconsistent or incomplete values across your datasets.
Whether you need to normalize formats, enrich information, resolve duplicates, or reconcile conflicting entries, Actions enable you to clean and refine your data with precision – ensuring reliable, high-quality outputs for all downstream processes.
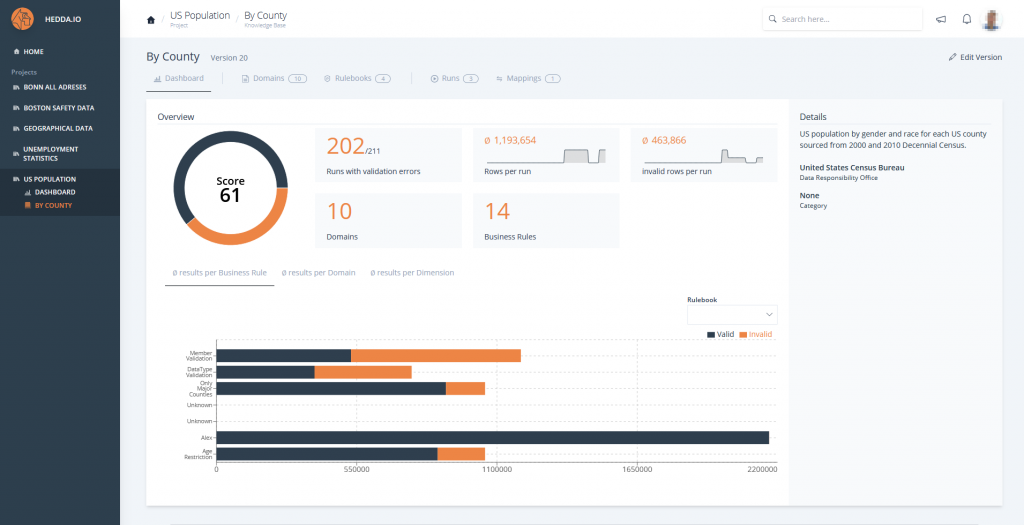
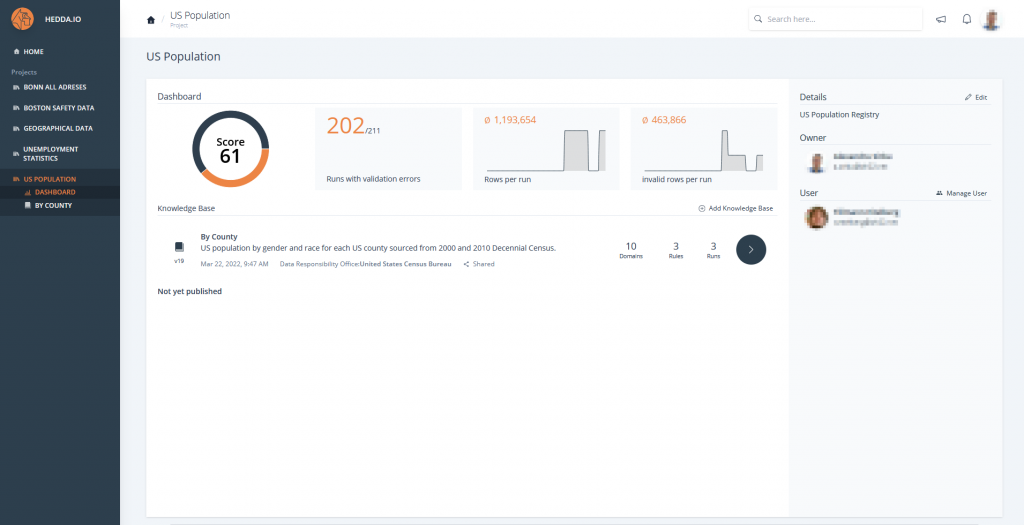
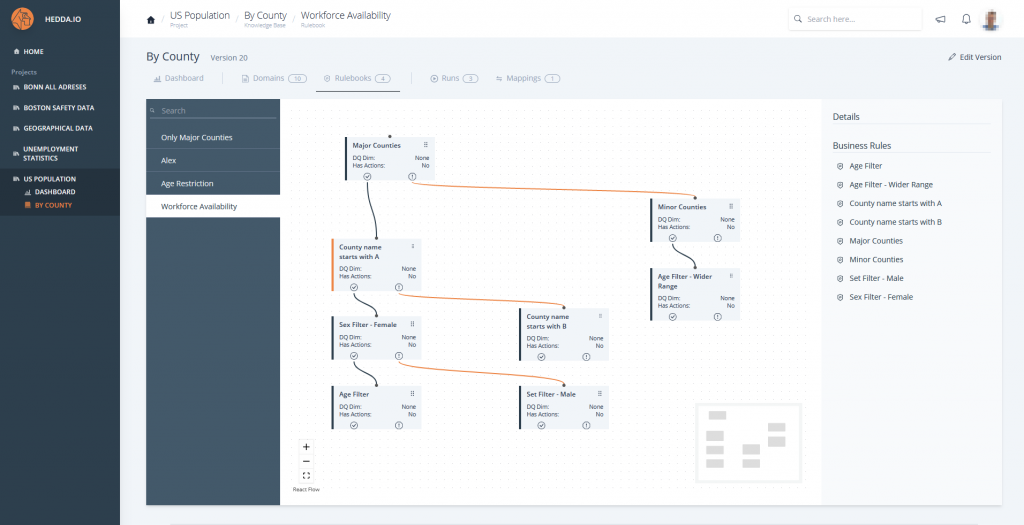
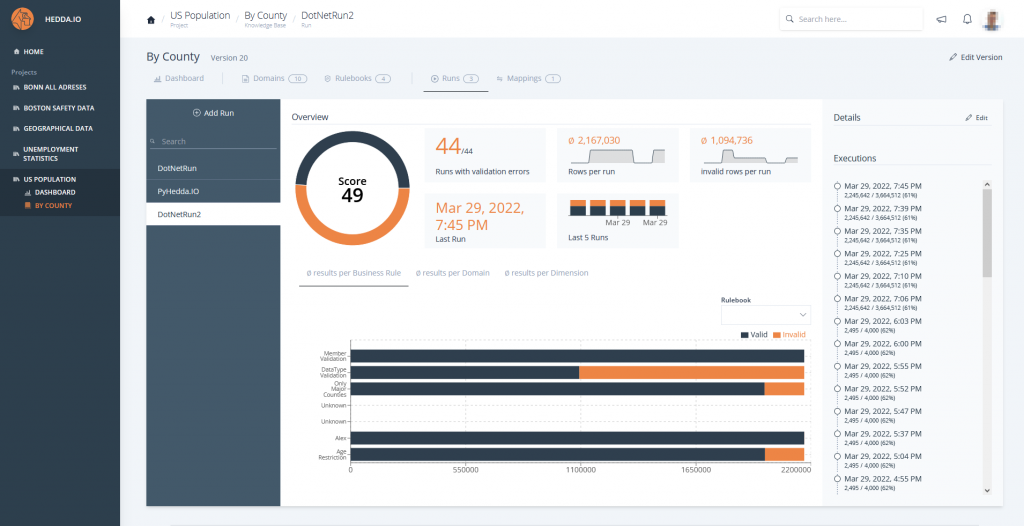
From simple business rules to highly sophisticated, multi-layered rule books, HEDDA.IO gives you a powerful way to operationalize your domain expertise. Define clear validation logic, combine rules into structured collections, and apply them consistently across all your data assets.
Rule Books allow you to capture complex relationships, dependencies, and business constraints – ensuring that incorrect, inconsistent, or suspicious data is detected early and reliably. This turns your domain knowledge into an automated quality gate, strengthening data integrity and enabling trustworthy analytics throughout your organization.
HEDDA.IO seamlessly integrates with Git to bring version control, collaboration, and full auditability to your data quality workflows.
By connecting your rule definitions, domain knowledge, actions, and configuration assets to a Git repository, every change becomes transparent, traceable, and fully reversible.
Teams can work collaboratively on shared artifacts, manage updates through pull requests, and align data quality logic with existing DevOps processes.
This ensures consistent deployment across environments, supports CI/CD pipelines, and provides a secure, governed lifecycle for all DQ-related assets – from initial drafts to production-ready configurations.
With Git Integration, HEDDA.IO enables you to treat data quality as code: structured, maintainable, and built for scalable enterprise operations.