WELCOME TO HEDDA.IO
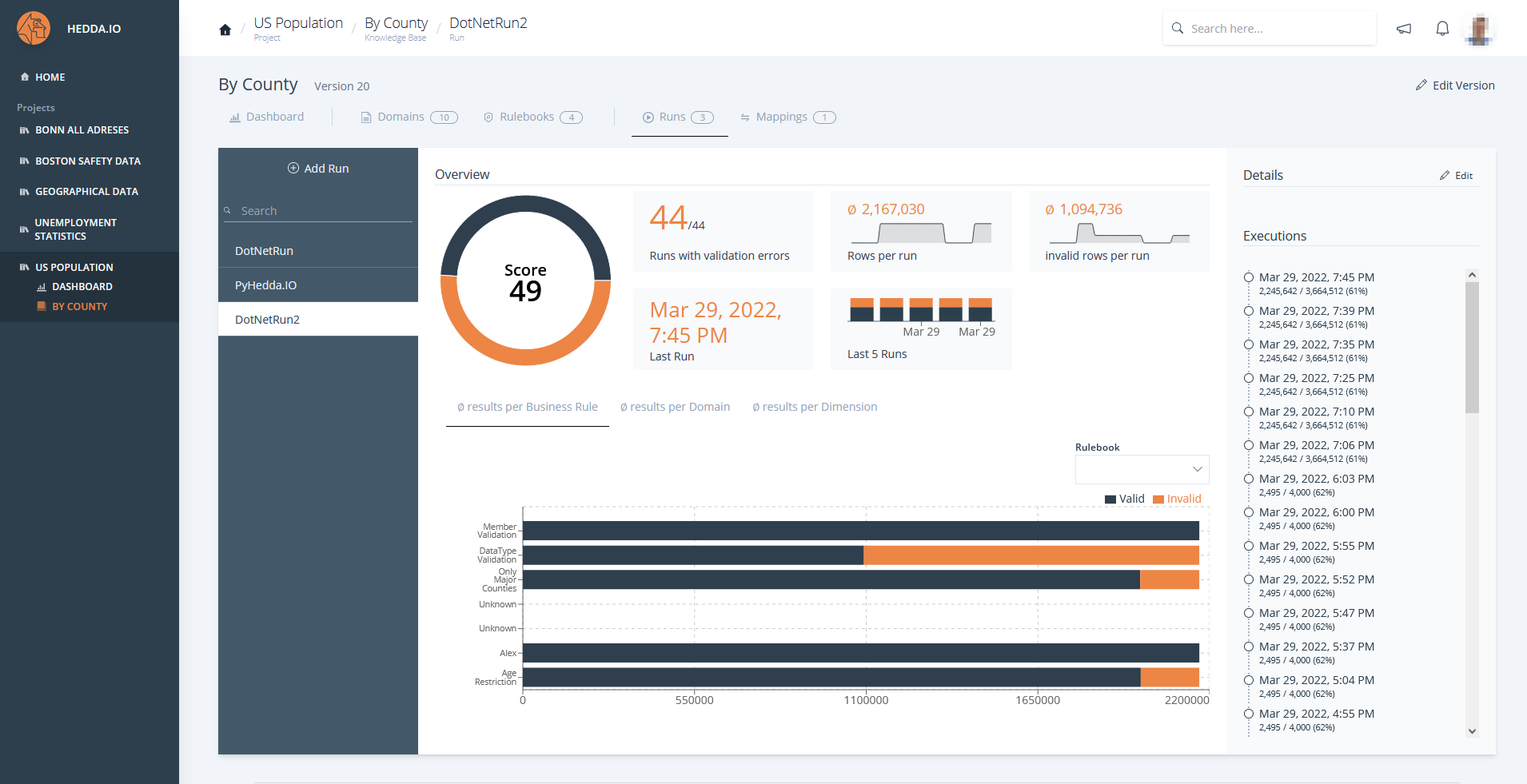
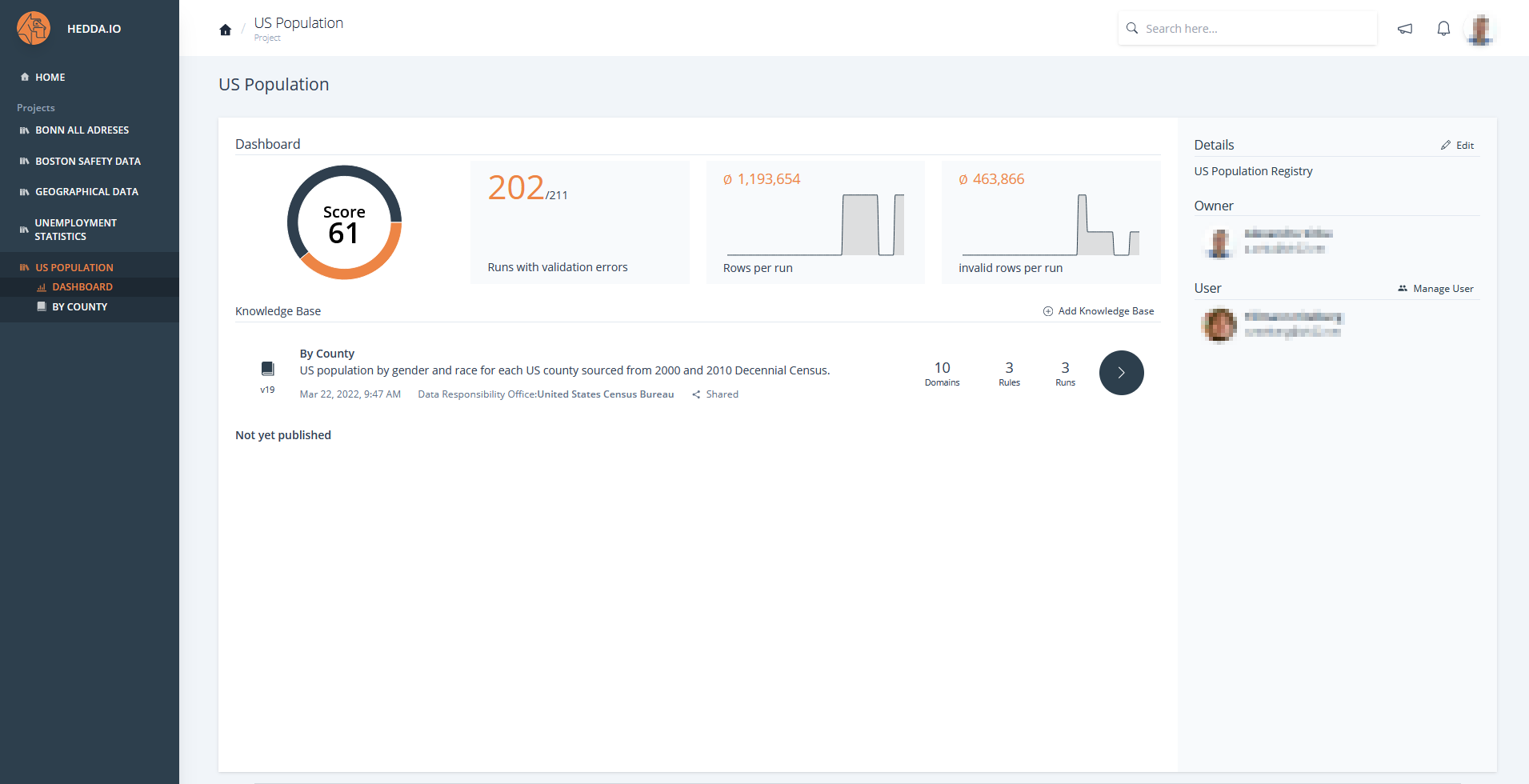
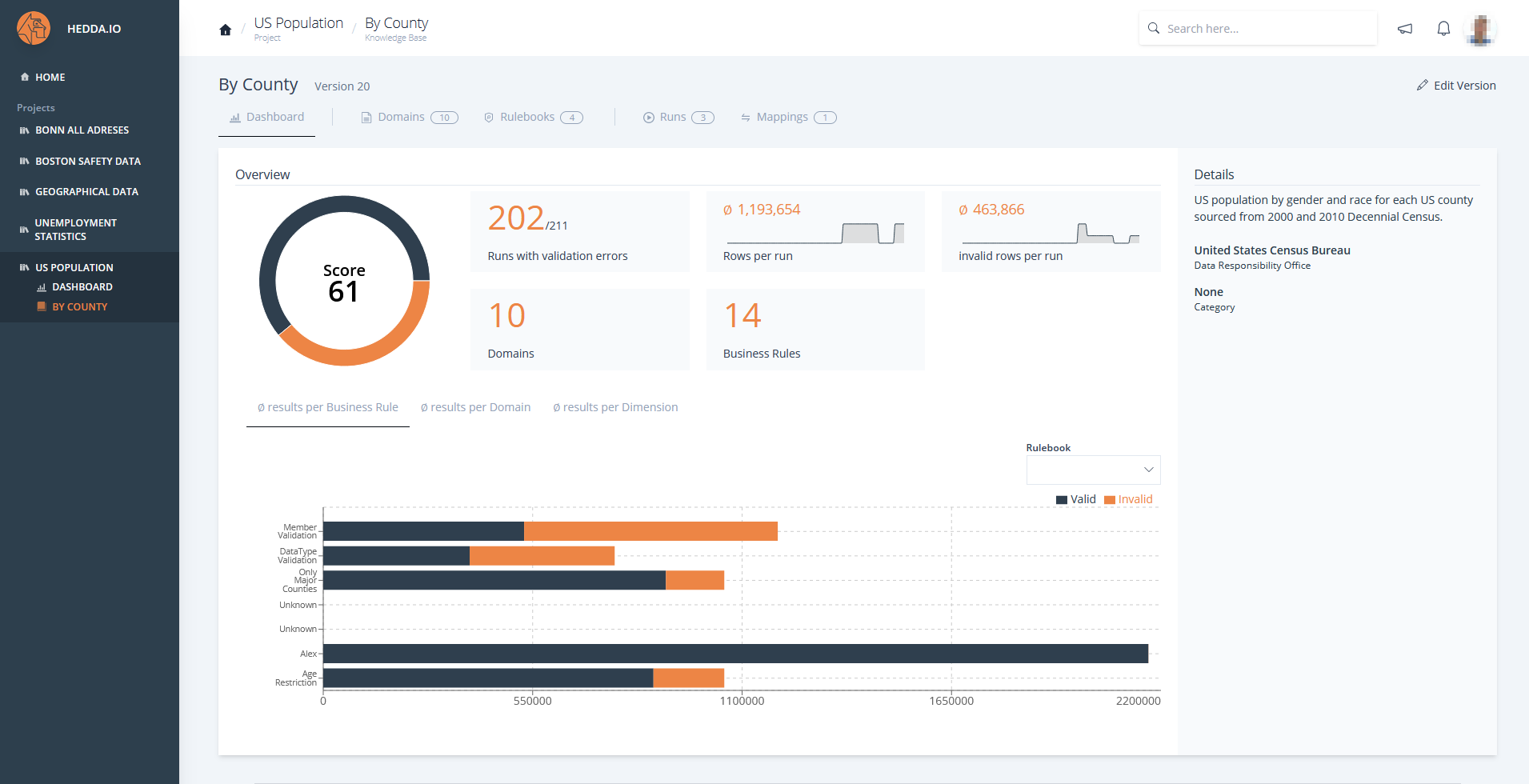
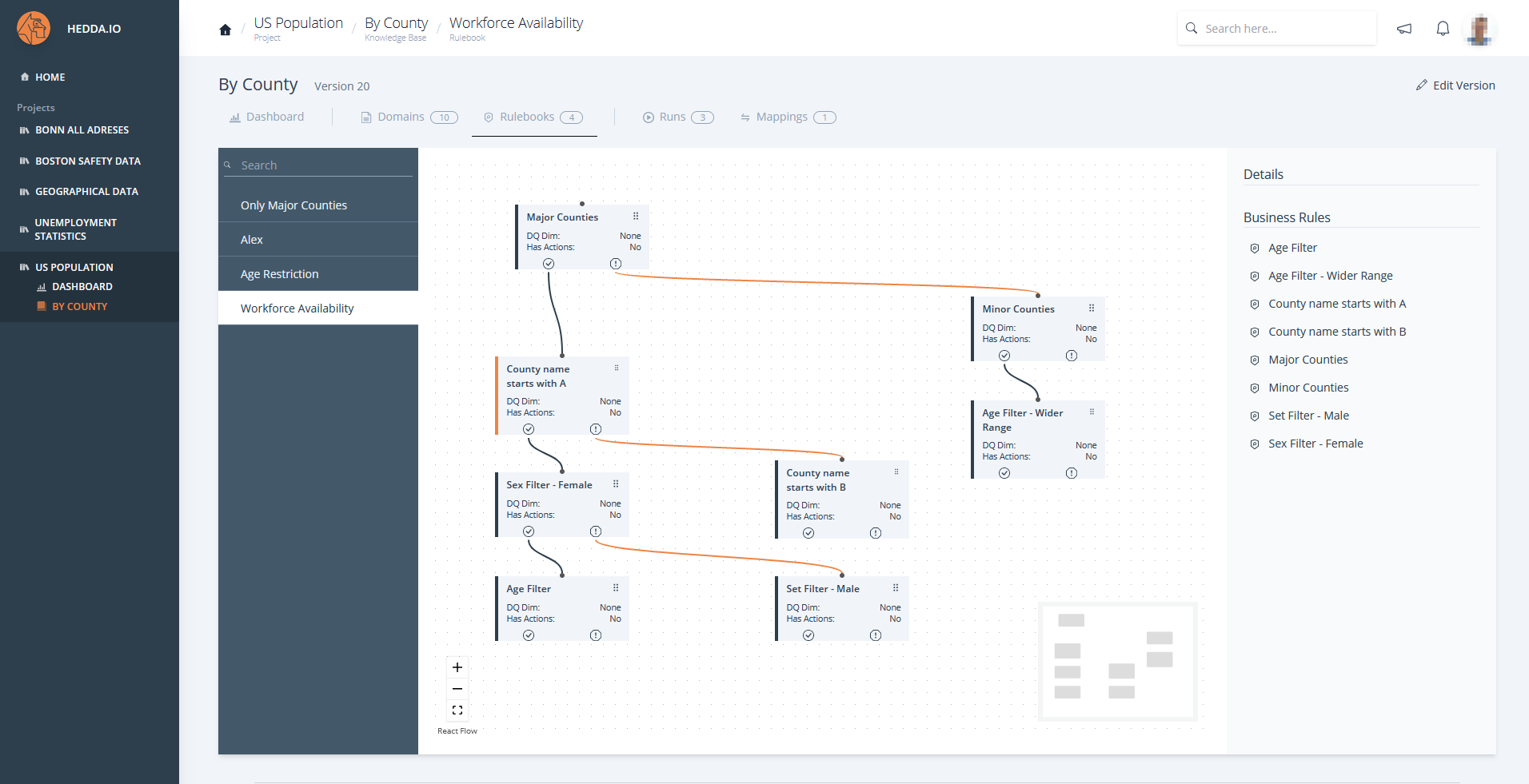
HEDDA.IO is a central data quality management solution that connects departments, data stewards and data engineers. It helps to easily integrate standardization, cleansing, matching and enrichment tasks into existing processes.
Core Functions & Technologies
Notebook integration
We use high-performance runners, in order to integrate HEDDA.IO into existing processes of a Modern Data Stack in the best possible way. The HEDDA.IO runners exist for pyspark and .NET and can therefore be used without any problems in Databricks, Azure Synapse Analytics and also in Visual Code together with .NET Interactive Notebooks.
Developers can thus extend their processes developed in Notebooks with HEDDA.IO. The full integration provides developers with IntelliSense and a meaningful widget for the results of an execution. All HEDDA.IO runners are designed to run on their respective systems (Databricks, Synapse, etc.) and not on the HEDDA.IO services.
Comprehensive statistics

Good data quality within companies is based, among other things, on uniform, clearly defined rules and well-maintained master or reference data that are applied to the company data for validation and cleansing.
However, the only way for companies to know how good the quality of the data will turn out in the end is through comprehensive statistics and information over the entire life cycle of their data – freely according to the much-quoted saying in IT: “You can’t control what you can’t measure”.
Business Rules
The application of business rules enables the targeted validation and transformation of data. HEDDA.IO checks standard business rules, such as the data types or the defined members of a domain, for each execution.
In addition, however, simple rules are also often used, including for example: “Expect column values not to be NULL”. In HEDDA.IO, over 40 data type-specific conditions can be applied to create rules ranging from simple to very complex. In addition, you can nest expressions with if-then structures, so there are almost no limits to the logic you can define.


Introducing Native Git Integration in HEDDA.IO 2.0
Introducing Native Git Integration in HEDDA.IO 2.0 A New Era of Collaboration, Control, and CI/CD for Knowledge Bases With HEDDA.IO 2.0, we are proud to introduce full Git-based integration for project storage and [...]

Machine Learning and AI – Built on Sand without Data Quality
Machine Learning and AI – Built on Sand Without Data Quality Why Dirty Data Silently Undermines Even the Smartest Models The rise of Machine Learning (ML) and Artificial Intelligence (AI) has changed what [...]

HEDDA.IO goes FabConEurope 2025
🔔𝗛𝗘𝗗𝗗𝗔.𝗜𝗢 𝗶𝘀 𝗮 𝗚𝗼𝗹𝗱 𝗦𝗽𝗼𝗻𝘀𝗼𝗿 𝗮𝘁 𝘁𝗵𝗲 𝗘𝘂𝗿𝗼𝗽𝗲𝗮𝗻 𝗠𝗶𝗰𝗿𝗼𝘀𝗼𝗳𝘁 𝗙𝗮𝗯𝗿𝗶𝗰 𝗖𝗼𝗺𝗺𝘂𝗻𝗶𝘁𝘆 𝗖𝗼𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲 𝟮𝟬𝟮𝟱. We’ll be in Vienna from 𝗦𝗲𝗽𝘁𝗲𝗺𝗯𝗲𝗿 𝟭𝟱–𝟭𝟴. Expect deep dives, real talk, and a chance to connect with the brightest [...]

