
Manage Data Quality with Delta Live Tables
In today’s data-driven business landscape, data quality is essential for organisational success. It creates the basis for informed decisions and strategic planning and ensures smooth project execution. Poor data quality, on the other hand, can lead to operational inefficiencies, inaccurate analyses, and misguided strategies.
Innovative solutions like Delta Live Tables (DLT) are transforming data handling by efficiently managing continuous data influx with real-time updates. At the same time, HEDDA.IO enhances data quality management with features like data profiling, monitoring, cleansing, and validation, ensuring data accuracy and consistency. DLT, part of Databricks Delta built on Apache Spark, excels in handling large, continuously updated datasets by storing only new changes (“deltas”). This real-time efficiency is complemented by HEDDA.IO, a comprehensive data quality management tool. HEDDA.IO enhances accuracy, consistency, and reliability through features like data profiling, monitoring, cleansing, and standardisation. Together, these tools provide a robust solution for maintaining high-quality data in dynamic business environments.
Feature Overview
In data management, maintaining high data quality is a pressing challenge, especially with large volumes of data. The management of vast and varied data sets often involves complex processes that can be prone to errors. Delta Live Tables (DLT) and HEDDA.IO team up to address issues like inconsistencies and inaccuracies. DLT automates data pipeline processes with integrated quality checks, while HEDDA.IO offers advanced data profiling, cleansing, and validation. Together, they ensure accurate and reliable data for decision-making and analytics.
Key Benefits and Advantages:
This integration not only ensures high data quality but also aids in meeting regulatory compliance standards, enhancing overall data security and integrity.
In short, the integration of Delta Live Tables with HEDDA.IO data quality capabilities represents a groundbreaking advancement in data management. This powerful combination leads to smarter business strategies, heightened operational efficiency, and a significant competitive advantage by harnessing the full potential of high-quality data.
So, How Does it Work?
Now, let’s look at how we can utilise the capabilities of Delta Live Tables and HEDDA.IO by integrating them together in a step-by-step manner.
To effectively integrate both tools we need 4 main components:
- A well-defined HEDDA.IO project.
- A Databricks workspace in premium capacity.
- A configured notebook to use in DLT pipeline.
- A Pipeline.
Let’s Start
You begin by creating a project in HEDDA.IO where all your domains, business rules, data links, runs and mappings are well defined.
A guide on how to use and navigate HEDDA.IO is available in the Documentation.
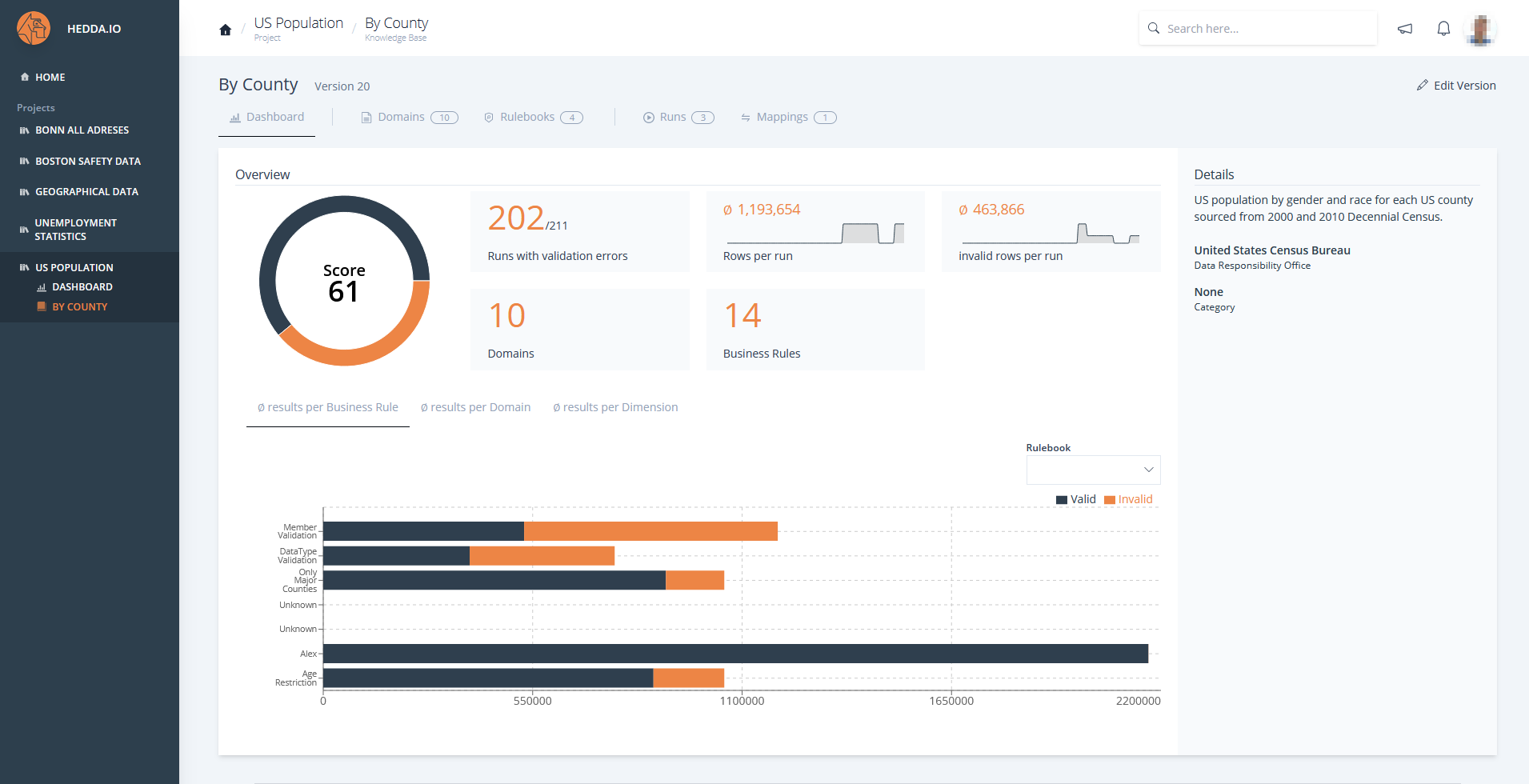
Once the project definitions are ready take note of your project name, knowledge base name, run name and move to the next step.
To utilize Delta Live Tables within Azure Databricks, opting for the Premium pricing tier is required as it’s exclusive to this level. Simply sign in to the Azure Portal and look up the Azure Databricks service within the Azure Marketplace. When setting up Azure Databricks, it’s necessary to designate a subscription and a resource group where Azure Databricks will be established.
A detailed guide on how to create a Databricks Workspace in Azure is available HERE.
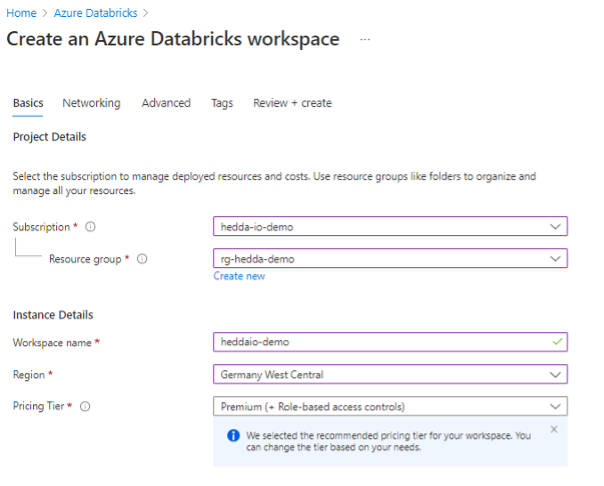
Configure Network or Advanced settings for additional security.
Once you configured all settings, click Review + Create button to view the deployment summary again and check the configurations.
To create workflows with Delta Live Tables, you need to create a notebook within Azure Databricks. Inside the notebook specify all the necessary data transformation needed for specific requirements.
In order to use the HEDDA.IO library in your notebook, you need to install the corresponding Python wheel via pip within the notebook:
In addition to installing Hedda library, you need to import the corresponding methods.
from pyheddaio.workflow import Hedda
from pyheddaio.management import DataContract
from pyheddaio.utils import log
from pyheddaio.config import CONFIG
To configure Hedda inside the notebook provide the Hedda project name, Knowledge base name, Run name, Hedda url, Hedda Api Key, Single row processing url and Api Key.
hedda.use_project(‘{PROJECTNAME}’)
hedda.use_knowledge_base(‘{KNOWLEDGEBASE}’)
hedda.use_run(‘{RUN}’)
hedda.begin_execution()
Within Delta Live Tables “Expectations” are defining data quality constraints on the contents of a dataset. With expect, expect or drop and expect or fail, individual expectations can be defined using Python to define a single data quality constraint. HEDDA.IO has been fully integrated here with a UDF and the Single Row Processing Runner, so that the Delta Live Tables can be extended with HEDDA.IO Expectations.
comment=”Silver Table “,
table_properties={
“quality”: “silver”
)
@hedda.dlt_expectations
def data_validated():
data = dlt.read(“”)
data = hedda.add_validation_columns(data)
return data
Once the notebook is configured we can now move to the last step of creating the DLT pipeline.
In order to run the code inside the notebook as a Delta Live Table, a pipeline must be created in Databricks. To do that go to the home page of your Databricks workspace and find Delta Live Tables tab and click create pipeline.
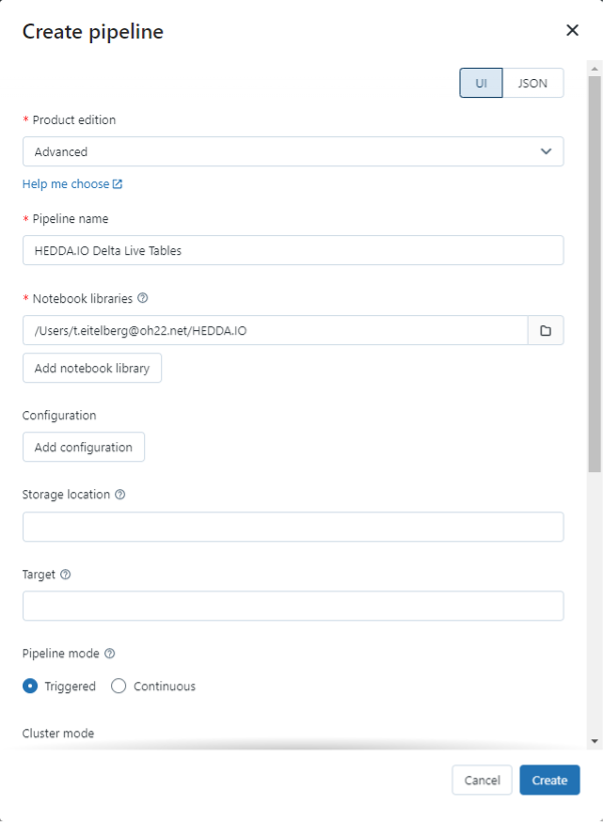
For the simplest generation of a corresponding pipeline, it is enough to define the notebook and give the pipeline a name. For a detailed configuration, the product edition can be changed for the execution, the configuration can be adapted, or a dedicated storage location can be defined.
The pipeline can then be executed in a triggered mode, i.e., batch based on an event, or for streaming data it can also run in a continued mode.
After running the pipeline, the results can be viewed directly in the pipeline details.
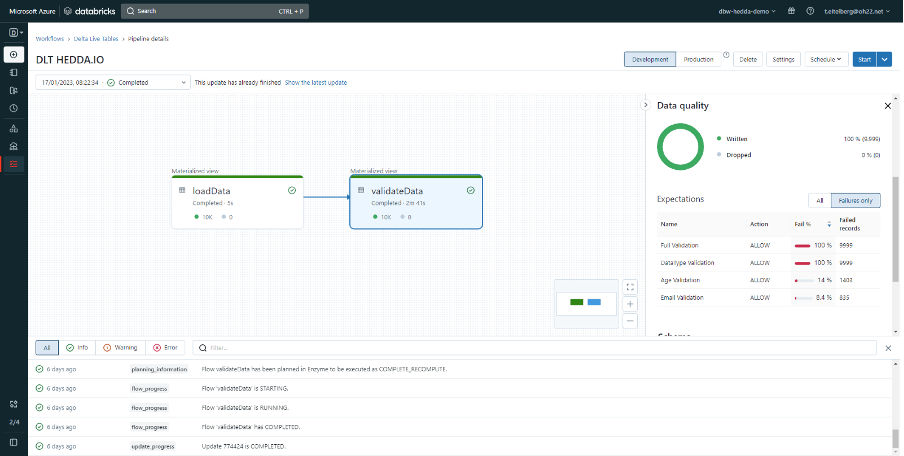
By clicking on the corresponding activity within the notebook the user can view detailed statistics.
Key Considerations
When integrating Delta Live Tables (DLT), it’s crucial to keep in mind several key aspects to ensure effective implementation and optimal use. First, remember that Delta Live Table is a functionality exclusive to Databricks, and a premium workspace capacity is required for its implementation. It’s important to note that notebooks designed for DLT cannot be run interactively; they can only be executed as part of the pipeline. Additionally, these notebooks should use either Python or SQL as the primary programming language, as using magic commands like %sql or %python will result in errors. Finally, when it comes to installing libraries using pip, this should be done right at the start of the notebook, specifically in the first command cell, to ensure smooth operation and integration.
Use Cases
The combined capabilities of Delta Live Tables (DLT) and Hedda.io find their utility in a variety of real-world scenarios. Integration of Hedda and DLT can enhance data quality and management across diverse industries. Here are some illustrative use cases:
In healthcare, patient data needs to be accurate and up-to-date for effective treatment and research. DLT can handle large volumes of patient data, and Hedda.io ensures its accuracy and compliance with health regulations. This leads to better patient care, more accurate research findings, and adherence to healthcare standards and privacy laws.
Financial institutions need to detect and prevent fraudulent activities quickly to protect their customers and assets. DLT can process transaction data in real-time, while Hedda.io ensures the accuracy and consistency of this data. This combination is crucial for identifying suspicious patterns. Banks and financial services can rapidly detect and respond to potential fraud, minimizing financial losses and maintaining customer trust.
In the world of sports, data drives decisions from player performance analysis to fan engagement strategies. DLT can handle real-time data from games, like player statistics and match outcomes. Hedda.io ensures this data is accurate and consistent, crucial for team performance analysis and scouting. Teams can make data-driven decisions about player training, game strategies, and even in predicting and preventing injuries. Accurate data also enhances fan experiences through personalized content and statistics.
Companies need to manage their supply chains efficiently to ensure timely delivery and reduce costs. DLT tracks goods throughout the supply chain in real time, while Hedda.io ensures data accuracy, vital for logistics planning. This leads to optimized logistics, reduced delays, and cost savings, enhancing overall supply chain efficiency.
These are only a few of many examples of where the integration of these two tools can be used. To enable the ability to improve operational efficiency, decision-making, and customer satisfaction through enhanced data management, the versatility of Delta Live Tables and Hedda.io can be used across various industries.
Conclusion
The synergy between Delta Live Tables and HEDDA.IO presents a significant opportunity in data management. Delta Live Tables offer real-time data processing and automation, ensuring efficient data flow, while HEDDA.IO adds rigorous data quality checks and validations for accuracy. Together, they provide a comprehensive solution for modern data challenges, enhancing data quality, regulatory compliance, and efficiency. This integration empowers organizations to make informed decisions based on reliable data, unlocking the full potential of their information for innovation and success in today’s data-driven world.




{kind=link}
{kind=link}
{kind=link}